Autoregressive Styled Text Image Generation, but Make it Reliable

Abstract
Generating faithful and readable styled text images (especially for Styled Handwritten Text generation - HTG) is an open problem with several possible applications across graphic design, document understanding, and image editing. A lot of research effort in this task is dedicated to developing strategies that reproduce the stylistic characteristics of a given writer, with promising results in terms of style fidelity and generalization achieved by the recently proposed Autoregressive Transformer paradigm for HTG. However, this method requires additional inputs, lacks a proper stop mechanism, and might end up in repetition loops, generating visual artifacts. In this work, we rethink the autoregressive formulation by framing HTG as a multimodal prompt-conditioned generation task, and tackle the content controllability issues by introducing special textual input tokens for better alignment with the visual ones. Moreover, we devise a Classifier-Free-Guidance-based strategy for our autoregressive model. Through extensive experimental validation, we demonstrate that our approach, dubbed Eruku, compared to previous solutions requires fewer inputs, generalizes better to unseen styles, and follows more faithfully the textual prompt, improving content adherence.
Method
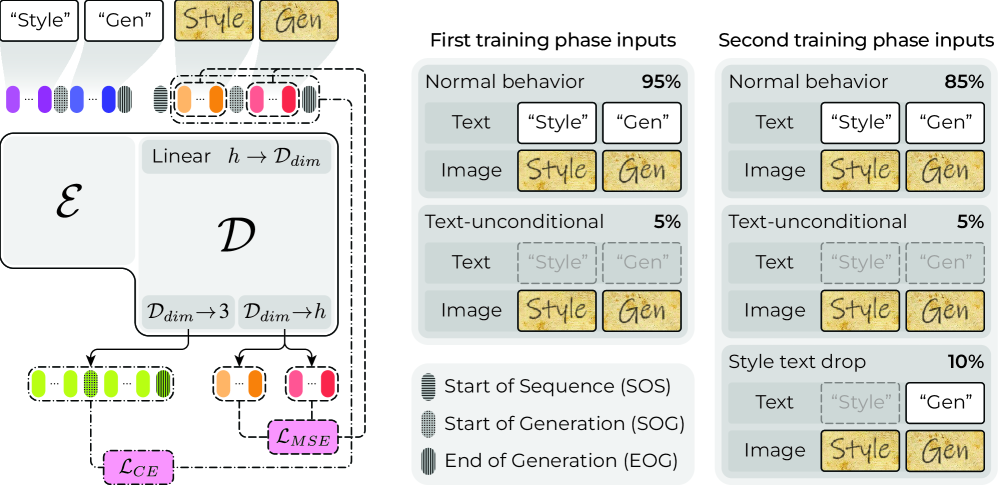
Eruku Training Framework. We condition generation on the textual content of a style image, the generation text, and the style image itself. Eruku learns to generate images containing the generation text with the same writing style as the style image. The model can work without style text by using synchronization tokens to separate sequence components.
Key Features
🎯 Optional Style Text
Unlike previous methods, Eruku can generate styled text images without requiring the transcription of the style image, making it more practical for real-world applications.
🛑 Explicit Stopping
Introduces a dedicated end-of-generation token instead of relying on heuristics, improving generation efficiency and reliability.
✨ CFG-Inspired Strategy
Employs Classifier-Free Guidance on textual inputs to enforce better adherence to the desired text sequence without auxiliary networks.
Results

Qualitative Results. Eruku generates high-quality styled text images across different datasets (IAM, CVL, RIMES) with accurate text content and faithful style reproduction. The model works on both handwritten and typewritten styles.
Quantitative Comparison
Eruku demonstrates significant improvements over the previous state-of-the-art autoregressive method (Emuru):
- Better Content Adherence: Lower ΔCER (Character Error Rate difference) showing more faithful text generation
- Improved Style Fidelity: Lower HWD (Handwriting Distance) indicating better style reproduction
- Fewer Required Inputs: Can operate without style text transcription
- More Robust: Better performance even with noisy OCR-generated style text
BibTeX
@inproceedings{zaccagnino2026eruku,
title={{Autoregressive Styled Text Image Generation, but Make it Reliable}},
author={Zaccagnino, Carmine and Quattrini, Fabio and Pippi, Vittorio and Cascianelli, Silvia and Tonioni, Alessio and Cucchiara, Rita},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year={2026}
}